Left Skewed Histogram: A Comprehensive Guide to Understanding, Interpreting, and Applying Skewed Data Distributions
One pattern that consistently challenges even seasoned professionals is the left-skewed histogram. In my years of consulting and teaching, I’ve seen how understanding these asymmetrical distributions — a key skill often honed through six sigma certification — can be a game-changer for businesses and project managers alike.
Here’s what you’ll learn
- The fundamentals of left-skewed histograms and how to identify them
- The critical relationship between mean, median, and mode in left-skewed distributions
- Real-world examples and applications across various industries
- Step-by-step techniques for analyzing and interpreting left-skewed data
- Common pitfalls to avoid and advanced strategies for handling skewed distributions
What is a Left Skewed Histogram?
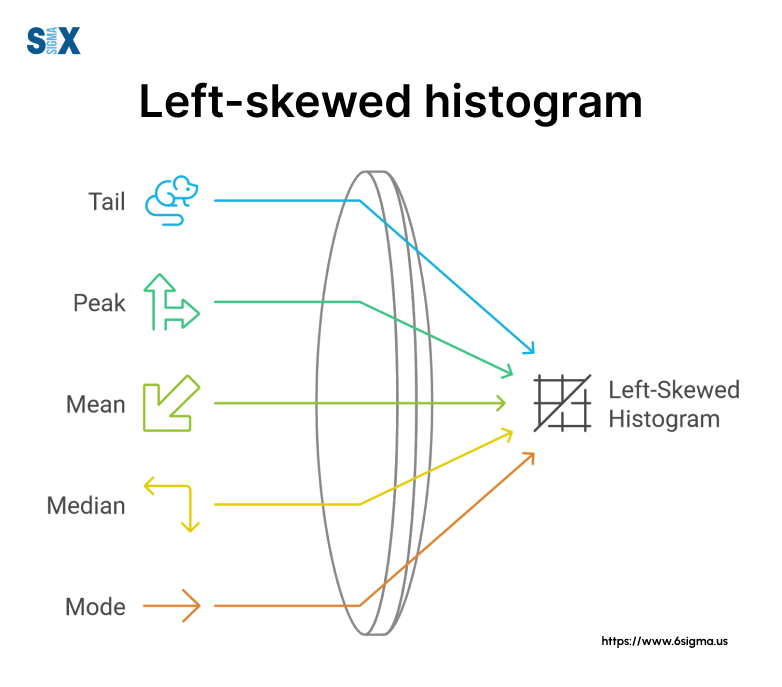
A left-skewed histogram, also known as a negatively skewed histogram, is a graphical representation of data where the tail of the distribution extends towards the left side, with the bulk of the data concentrated on the right.
In simpler terms, when you look at a left-skewed histogram, you’ll notice that the “peak” of the data is shifted towards the right, while there’s a longer tail stretching to the left.
Key characteristics to identify in a left-skewed histogram include:
- The peak (mode) is on the right side of the center.
- The tail extends longer on the left side.
- The mean is typically less than the median.
To help visualize this, imagine you’re looking at a dataset of employee salaries in a company. You might see a large group of employees with higher salaries on the right, and a smaller number of employees with much lower salaries creating that left tail.
Comparing Left Skewed Histogram with Other Distribution Types
To truly understand what a left-skewed histogram looks like, it’s helpful to compare it with other common distribution types I’ve encountered in my consulting work:
- Normal Distribution: This is the classic “bell curve” shape, symmetrical on both sides. Unlike a left-skewed histogram, the mean, median, and mode are all equal in a normal distribution.
- Right Skewed Distribution: This is the mirror image of a left-skewed histogram. The tail extends to the right, with the bulk of the data on the left side.
- Symmetrical Distribution: While similar to a normal distribution, not all symmetrical distributions are normal. The key is that they’re balanced on both sides, unlike our left-skewed histogram.
Understanding these differences is crucial. In my work with companies like Intel and Motorola, I’ve seen how misinterpreting the type of distribution can lead to costly mistakes in process improvement initiatives – a risk mitigated by the rigorous analytical training provided in six sigma certification programs.
Ready to deepen your understanding of data distributions and their impact on business decisions? Enroll in a short course on statistical analysis and data interpretation.
Properties and Characteristics of a Left Skewed Histogram
Understanding the properties and characteristics of left-skewed histograms is crucial for effective data analysis and decision-making. Let’s dive into these key aspects that I’ve seen make a significant difference in projects across various industries.
Mean, Median, and Mode Relationship
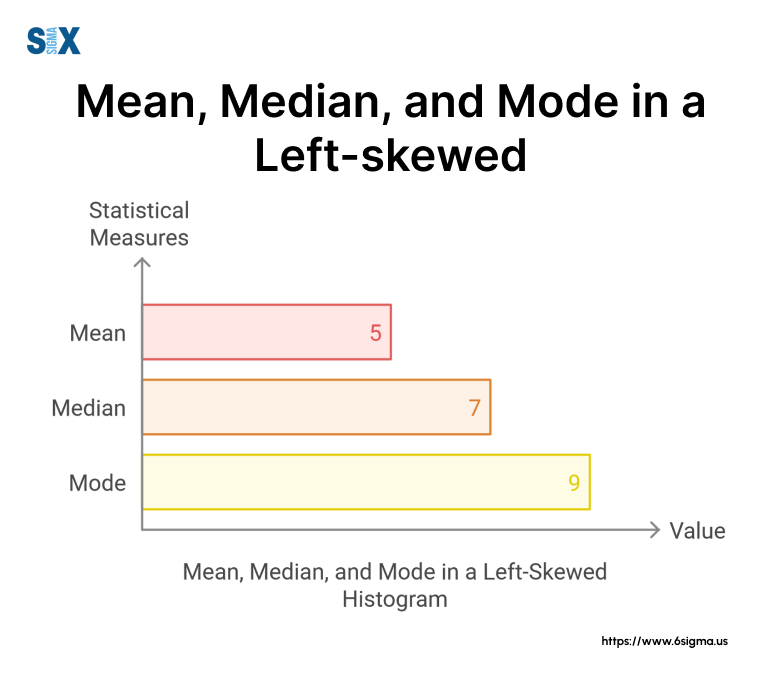
One of the most distinctive features of a left-skewed histogram is the relationship between its mean, median, and mode. In my workshops, I often use this relationship as a quick identifier for left skewness:
Mean < Median < Mode
This relationship is quite different from what we see in normal distributions, where these three measures of central tendency are typically equal. Let me break it down based on my experiences:
- Mean: In a left-skewed histogram, the mean is pulled towards the left tail by the smaller values. I’ve seen this cause confusion in salary analyses, where the average (mean) salary can be misleadingly low due to a few entry-level positions.
- Median: The median, being the middle value, is less affected by extreme values. It’s often a more reliable measure of center in skewed distributions.
- Mode: This is the peak of our distribution, representing the most common value. In left-skewed histograms, it’s the rightmost of these three measures.
Tail and Peak Analysis
Understanding the tail and peak of a left-skewed histogram can provide valuable insights:
- Long Left Tail: This extended tail represents the less frequent, smaller values in our dataset. In my work with manufacturing processes, I’ve seen this tail represent rare defects or outlier performance issues.
- Peak Position: The peak (mode) is shifted towards the right side of the distribution. This indicates that the most common values in our dataset are on the higher end of the range.
Skewness Measurement
To quantify the degree of skewness, we use the skewness coefficient:
- Negative Skewness: A left-skewed histogram will have a negative skewness coefficient. The more negative the value, the more pronounced the left skew.
- Interpreting Values: In my experience, values between -0.5 and -1 indicate moderate skewness, while values below -1 suggest high skewness. However, these are general guidelines and can vary depending on the specific context of your data.
Key Properties of Left-Skewed Histograms
- The mean is less than the median, which is less than the mode
- The long tail extends to the left
- Peak (mode) is positioned on the right side
- Negative skewness coefficient
- The majority of data points are on the right side
- Fewer, but more extreme, low values on the left
Understanding these properties of left-skewed histograms is essential for accurate data interpretation.
Interpreting a Left Skewed Histogram: A Step-by-Step Guide
In my years of consulting and teaching Six Sigma methodologies, which forms the core of six sigma certification, I’ve found that interpreting left-skewed histograms is a crucial skill for data-driven decision-making.
Identifying the Distribution of Shape
The first step in interpreting a left-skewed histogram is recognizing its unique shape. Here’s what to look for:
- Longer tail on the left side
- Peak (mode) shifted to the right
- Gradual slope on the left, steeper slope on the right
Remember, a left-skewed histogram doesn’t always mean there’s a problem. In some cases, it’s the expected distribution. For instance, in a project, we found that the distribution of time-to-failure for certain products was naturally left-skewed.
Analyzing Central Tendency Measures of a Left Skewed Histogram
Understanding the relationship between mean, median, and mode is crucial:
- Mean < Median < Mode
- Mean is pulled towards the left tail
- Median is often more representative of the typical value
In a Six Sigma project, we used this relationship to identify discrepancies in customer satisfaction scores that weren’t apparent from the average alone. This type of practical data application is a core component of six sigma green belt certification, where participants learn to manage projects and utilize statistical tools effectively.
Understanding Data Concentration and Outliers
In a left-skewed histogram:
- Most data points cluster on the right side
- Outliers typically appear on the left side
- The left tail often represents rare but significant events
During a process improvement initiative, we identified critical quality issues by focusing on these left-tail outliers. Understanding why these outliers occurred required diving deeper, a process thoroughly covered in root cause analysis training.
Contextualizing the Skewness
Always consider the context of your data:
- What does the left tail represent in your specific scenario?
- Is the skewness expected or a sign of an underlying issue?
- How does the skewness impact your business goals?
Common Pitfalls of a Left Skewed Histogram and How to Avoid Them
Be aware of these common mistakes:
- Focusing solely on the mean: Always consider median and mode too
- Ignoring outliers: They often hold valuable insights
- Assuming normality: Many real-world processes aren’t normally distributed
In a project, we initially missed a crucial insight by falling into the “normality assumption” trap. Always question your assumptions!
Want to apply these interpretation techniques to real-world scenarios? Get hands-on experience with advanced statistical techniques with our Lean Six Sigma Green Belt certification.
Applications and Examples
These asymmetrical distributions often reveal critical insights that can drive business decisions and process improvements. Let me share some examples from my experience working with global corporations and government institutions.
Income Distribution Analysis
One of the most common examples of a left-skewed histogram is income distribution. In a project I led for a large multinational corporation, we analyzed employee salaries across different departments. The resulting left-skewed histogram revealed:
- A large cluster of mid-level salaries on the right
- A long tail to the left represents lower-paid entry-level positions
- A few extremely high salaries pull the mean lower than the median
This analysis helped the company identify potential pay equity issues and informed its compensation strategy.
Age-Related Data
During my work with healthcare organizations, I’ve often encountered left-skewed histograms in age-related data:
- Retirement Age: A slightly left-skewed histogram typically shows most people retiring around 65, with a tail extending to earlier retirements.
- Life Expectancy: When analyzing life expectancy data for a government health initiative, we found a left-skewed distribution with a peak around 80 years and a tail extending towards younger ages.
Academic Performance Metrics with a Left Skewed Histogram
In an educational consulting project, we analyzed student performance data:
- GPA distributions often show a left skew, with most students clustered around higher GPAs
- Standardized test scores can also exhibit left skewness, especially for advanced exams
Understanding these distributions helped institutions develop more effective support programs for struggling students.
Environmental Data
Environmental metrics frequently display left skewness:
- Pollution Levels: In a project for an environmental agency, we found that daily air quality readings often produced a left-skewed histogram, with most days having low pollution and a few high-pollution days creating the left tail.
- Rainfall: Analyzing rainfall data for an agricultural client revealed a left-skewed distribution, with most months having moderate rainfall and occasional drought periods forming the left tail.
Financial Markets
Stock returns typically show a left-skewed distribution:
- Most returns cluster around a slightly positive value
- The left tail represents occasional significant losses
- Rare but extreme positive returns create a slight right skew
Integrating lean fundamentals into financial analysis helps organizations streamline decision-making while accounting for skewed risk profiles.
These examples demonstrate the ubiquity and importance of left-skewed histograms across various fields. By recognizing and correctly interpreting these distributions, you can uncover valuable insights that drive informed decision-making in your organization.
Creating and Analyzing Left Skewed Histograms
Let me share some insights I’ve gained from working with companies and government institutions over the years.
Data Collection Considerations
When dealing with potentially left-skewed data, keep these points in mind:
- Sample Size: Ensure your sample is large enough to reveal the true distribution. In a project at Motorola, we initially missed a left skew due to insufficient data.
- Data Quality: Be vigilant about data accuracy. Identifying these outliers often requires root cause analysis training, which equips teams to systematically address underlying process issues.
- Time Frame: For time-series data, consider whether the skewness is consistent or varies over time. This was crucial in a long-term process improvement project.
Choosing Appropriate Bin Sizes for a Left Skewed Histogram
Bin size can significantly impact the appearance of your left-skewed histogram:
- Too few bins can mask the skewness
- Too many bins can create noise and obscure the overall pattern
- Consider using unequal bin widths for highly skewed data
I often use the square root of the sample size as a starting point for the number of bins, adjusting as needed based on the data’s characteristics.
Tools and Software for Histogram Creation
Over the years, I’ve used various tools to create left-skewed histograms:
- Excel: Great for quick visualizations. Use the Data Analysis ToolPak for basic histograms.
- R: My go-to for advanced statistical analysis. The ggplot2 package is excellent for customizable histograms.
- Python Libraries: Matplotlib and Seaborn are powerful for creating histograms, especially when dealing with large datasets.
- Minitab: A staple in Six Sigma projects, it offers robust histogram capabilities.
Best Practices for Visual Presentation
To effectively communicate your findings:
- Use clear labeling for axes and bins
- Include a legend if comparing multiple datasets
- Consider overlaying a normal distribution curve for comparison
- Use color strategically to highlight key areas of the distribution
Remember, the goal isn’t just to create a left-skewed histogram, but to use it as a tool for insight and decision-making. In my workshops, I always emphasize that the real value comes from interpreting the histogram in the context of your specific business challenge.
Additions to Left-Skewed Distributions
These topics are crucial for anyone looking to master data analysis and drive meaningful business improvements.
Transforming Left Skewed Histogram Data
In many Six Sigma projects, I’ve encountered situations where we needed to transform left-skewed data for further analysis:
- Log Transformation: Often effective for slightly left-skewed histograms, especially in financial data.
- Box-Cox Transformation: A powerful method I’ve used in manufacturing processes to normalize skewed data.
- Square Root Transformation: Useful for counting data that shows left skewness.
Remember, the goal of transformation is not just to achieve normality, but to make your data more amenable to statistical analysis while preserving its fundamental characteristics.
Statistical Tests for Skewed Data
When dealing with left-skewed distributions, traditional tests may not be appropriate. Here are some alternatives I frequently use:
- Mann-Whitney U Test: A non-parametric test I’ve applied in quality control projects.
- Kruskal-Wallis Test: Useful for comparing multiple groups with skewed data.
- Bootstrapping Methods: I’ve found these particularly valuable for estimating confidence intervals in skewed datasets.
Implications for Predictive Modeling
Left skewed data can significantly impact predictive models:
- In regression analysis, skewed residuals can violate assumptions and lead to unreliable predictions.
- For classification problems, skewed features may need special handling to prevent bias.
- Time series forecasting with left-skewed data often requires specialized models like GARCH.
During a project, we had to redesign our entire predictive maintenance model due to overlooked left skewness in equipment failure times.
Ethical Considerations in Interpreting Skewed Data
As data scientists and business leaders, we have an ethical responsibility to interpret skewed data correctly:
- Avoid cherry-picking metrics that hide important information in the left tail.
- Be transparent about the limitations of your analysis when dealing with skewed distributions.
- Consider the real-world implications of decisions based on skewed data, especially in sensitive areas like healthcare or finance.
Even a foundational awareness, often gained through introductory programs like six sigma white belt certification, helps emphasize the importance of careful interpretation and transparency.
These advanced topics underscore the complexity and importance of understanding left-skewed histograms in real-world scenarios. By mastering these concepts, you’ll be better equipped to extract valuable insights from your data and make informed decisions. Participating in six sigma certification programs helps individuals learn these concepts and add value to their organization.
Ready to dive deeper into advanced statistical methods and their applications? Focus on cutting-edge data analysis techniques for process improvement with a short course on Introduction to Graphical Analysis with Minitab.
Historical Context and Future Trends
As a Six Sigma Master Black Belt with over two decades of experience, I’ve witnessed firsthand the evolution of data analysis techniques, particularly in the realm of left-skewed histograms. Let’s take a journey through time and peek into the future of this crucial statistical tool.
Brief History of Skewed Distribution Analysis
The concept of skewed distributions dates back to the late 19th century, but its practical applications have grown exponentially:
- 1895: Karl Pearson introduced the concept of skewness in distributions.
- 1920s: R. Fisher developed methods for handling non-normal distributions.
- 1960s: Box-Cox transformations emerged, revolutionizing how we handle skewed data.
- 1980s: Robust statistical methods gained popularity, addressing challenges with skewed data.
During the 1990s, I saw a shift from avoiding skewed data to embracing it for deeper insights.
Emerging Applications in Big Data and Machine Learning
The big data revolution has brought new relevance to left-skewed histograms:
- Anomaly Detection: In cybersecurity projects I’ve led, left-skewed distributions often indicate potential threats.
- Predictive Maintenance: At companies like GE, we’ve used skewed time-to-failure distributions to optimize maintenance schedules.
- Customer Behavior Analysis: E-commerce giants are leveraging skewed purchase patterns for personalized marketing.
Machine learning algorithms are becoming more adept at handling skewed data, opening up new possibilities for automated analysis and decision-making.
Predicted Developments of a Left Skewed Histogram in Data Visualization Techniques
The future of left-skewed histogram analysis is exciting:
- Interactive 3D Visualizations: I’m seeing prototypes that allow users to “walk through” skewed distributions in virtual reality.
- Real-time Dynamic Histograms: Imagine dashboards that update left-skewed histograms as data streams, something we’re implementing in IoT projects.
- AI-assisted Interpretation: Tools that not only display left-skewed histograms but provide context-aware insights are on the horizon.

As we move forward, the ability to understand and leverage left-skewed histograms will become increasingly crucial. I can confidently say that mastering these concepts will be a key differentiator in data-driven decision-making.
Going Forward
As we wrap up our deep dive into left-skewed histograms, I want to emphasize the critical role these statistical tools play in modern business and project management. I’ve seen firsthand how understanding left-skewed distributions can lead to breakthrough insights and drive meaningful improvements.
Let’s recap the key points we’ve covered:
- We defined what a left-skewed histogram is and explored its unique characteristics.
- We examined the crucial relationship between mean, median, and mode in left-skewed distributions.
- We discussed real-world applications across various industries, from finance to manufacturing.
- We delved into advanced topics like data transformation and ethical considerations.
- Finally, we looked at the historical context and future trends in skewed data analysis.
Understanding left-skewed histograms is not just about statistical knowledge – it’s about gaining a deeper understanding of your processes, customers, and business environment.
If you’re ready to take your data analysis skills to the next level, consider exploring our advanced Six Sigma courses at SixSigma.us. Together, we can turn your data into actionable insights that drive real business results.
SixSigma.us offers both Live Virtual classes as well as Online Self-Paced training. Most option includes access to the same great Master Black Belt instructors that teach our World Class in-person sessions. Sign-up today!
Virtual Classroom Training Programs Self-Paced Online Training Programs



